内核笔记
调试
性能
知识点
RCU
entry
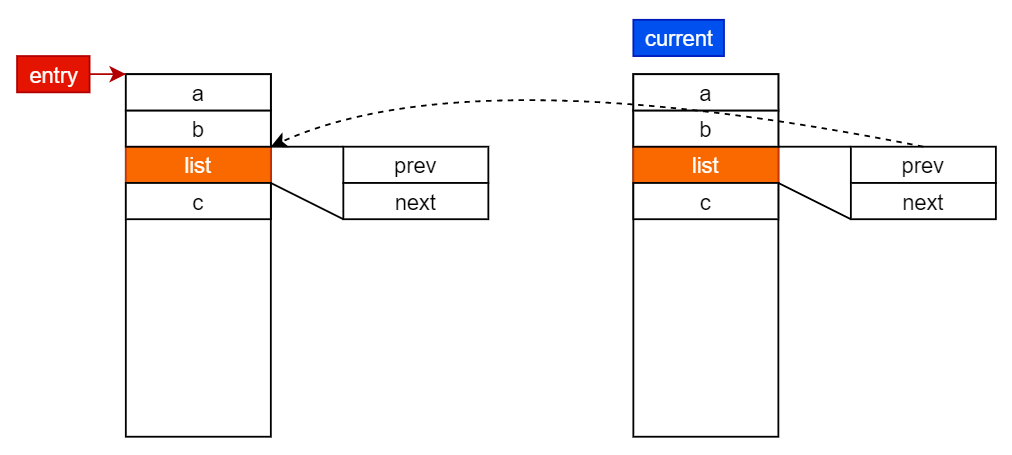
entry 在 linux 链表中表示一个条目。
list_entry()
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
通过结构体(type类型)中某个成员(member),和成员地址(ptr),得到结构体的首地址(entry)。
另:ptr 是 pointer 的意思,指针
实例:
last_tid = list_entry(tid_list->prev, struct ath_atx_tid, list);
list_first_entry()
无序链表任何一个节点都可以是头
大佬
知乎:
工作
读书
二刷《Linux内核设计与实现》
目标:
内存管理、进程管理、文件系统。
面试官:请谈谈linux内存管理
我们有一块内存,我们如何去使用它。
程序想要运行,必须加载到内存,因为磁盘太慢了。
那要怎么把进程加载到内存呢?放在内存的什么位置呢?
如果不加以管理,比方说进程A占用了地址0-100,进程B也去占用这部分内存,就会出问题。我们也不可能提前规划好,A 使用0-100,B 使用101-200。就算能规划,你还一个平台呢?又何别的程序冲突了。
一开始,内存是按段管理的,即段式存储。
所以引入了虚拟内存,每个进程,都认为所有内存地址空间都是自己的,自己想怎么用就怎么用。A 进程使用0-10000地址,B进程照样可以使用0-1000地址。那背后是怎样实现的呢?就是虚拟地址,MMU 把虚拟地址映射到实际的物理内存地址,A 的 10000 比方说映射到物理内存的 1000,B的1000比方说映射到物理内存的2000,所以A 和B 不冲突。但是A和B 是察觉不到这件事的,都是MMU在默默的工作。
那MMU具体是怎么做的呢?比方说A访问一段虚拟地址时,MMU就会看这段虚拟地址是否在物理内存上(通过页表),如果在物理内存上,就从物理内存上访问数据。如果发现页表上没有此条记录,说明该虚拟地址没有映射到实际的物理地址,这时就发生缺页中断,去查找可用的物理内存,做映射。
现在的进程非常占内存,动不动几个G ,十几个G ,物理内存就那么大,被占完了怎么办,这时候就要考虑把部分物理内存暂存到磁盘上,捣腾出空间,磁盘上的这部分空间就是交换分区。将谁的内存置换到磁盘上呢?这就依靠内存管理算法了,没有最好,只有合适。一般是将最久没有使用的,置换到磁盘。(和kill占内存最多的进程的差别)
另外一个问题,以什么为单位管理内存呢?太小也不好,太大也不好。
内存4K,
页、页框,
置换算法,
创建算法:是从内存地址从小到大查找,找到第一块满足的内存就分配呢?还是找到一块符合条件的最小的空闲内存呢?前者快,单容易产生内存碎片;后者慢,但内存碎片较少。
不管何种算法,随着时间推移,肯定会产生内存碎片,如何回收呢?
开始看书!!!!
少讲了内核空间地址范围,用户空间地址范围,以32位系统为例。
内核把物理页作为内存管理的最小单位。MMU(Memory Management Unit,内存管理单元,管理内存并把虚拟地址转换成物理地址的硬件)通常以页为单位进行管理。这也是页表名称的由来。从虚拟内存的角度来看,页就是最小单位。
大多数 32 位体系结构支持 4KB 的页,而 64 位体系结构一般会支持 8KB 的页。
这就意味着,在支持 4KB 页大小并有 1GB 物理内存的机器上,物理内存会被划分为 262144 个页。
内核用 struct page 结构表示系统中的每个物理页。结构位于<linux/mm.h>
virtual 字段是页的虚拟地址。
_count 字段存放页的引用计数。
这个数据结构的目的在于描述物理内存本身,而不是描述包含在其中的数据。
内核用这一数据结构来管理系统中所有的页,因为内核需要知道一个页是否空闲。
系统中的每个物理页都要分配一个这样的结构体。
物理内存分为三个区:ZONE_DMA、ZONE_NORMAL、ZONE_HIGHMEM
简历-性能优化:缓存一致性、使用 kmalloc() 代替 vmalloc() [第11章 vmalloc()]、内存池(类似slab机制)
kmalloc() –> 空闲链表 –> slab 分配器
看视频: 链接
重定位(非重定向)
保护
共享
代码中的地址都是虚拟(逻辑)地址,编译好的汇编或二进制也是虚拟地址,讨论的堆、栈、静态数据区、代码区也都是虚拟地址
重定向,就是程序地址使用偏移量,代替直接使用地址。
在执行对内存的访问之前,必须把它转换成物理地址。
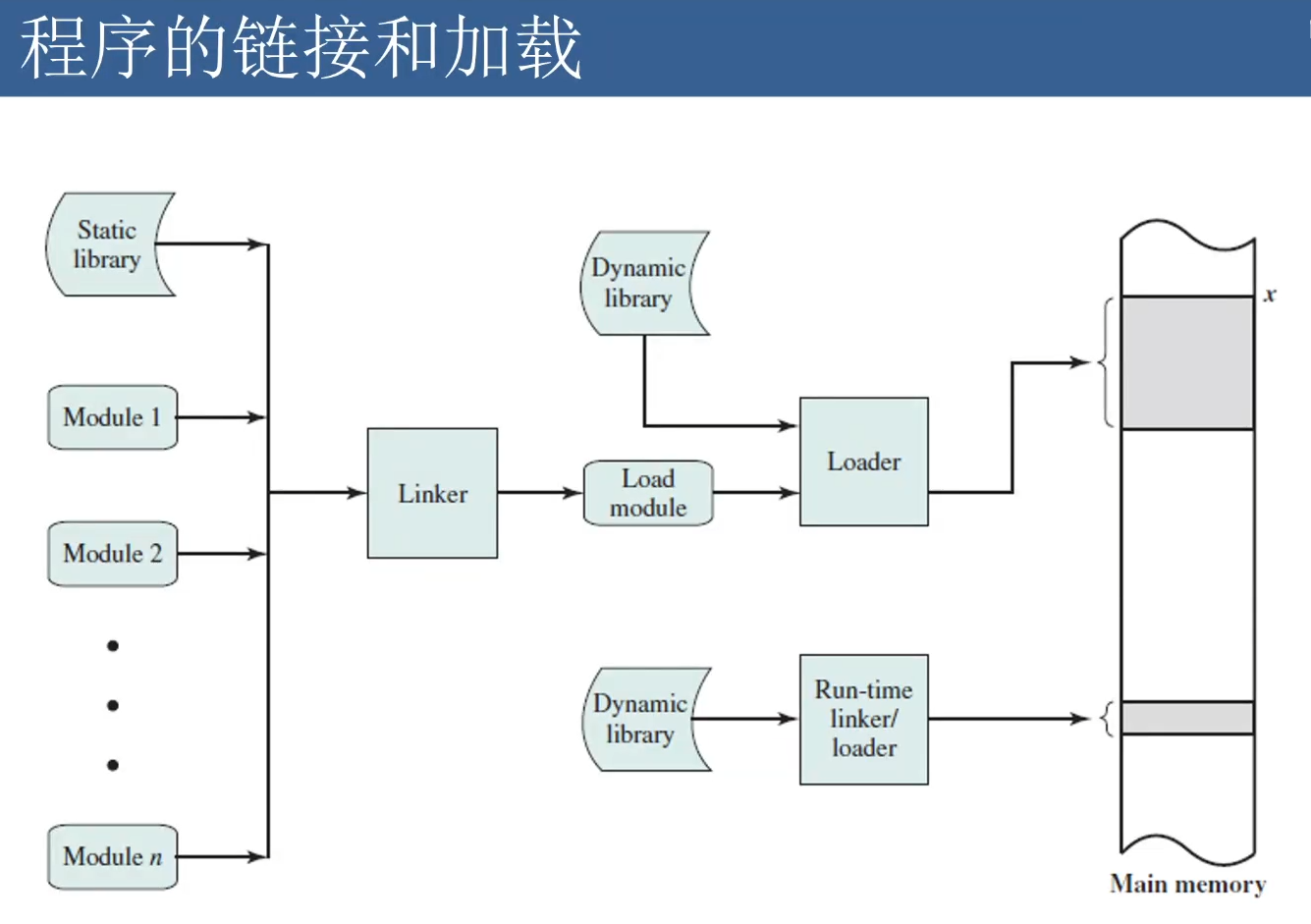
程序的链接和加载
特权模式
内存管理:
固定数量分区(等大小)。问题:支持的进程并发数量有限。有的进程很大,放不下;有的进程很小,占一个分区浪费。
👇
固定数量分区(大小不等的分区)。
👇
**动态分区。**进程需要多少内存,就分配多少内存,没有内部碎片。缺点:程序释放,产生外部碎片。解决办法:压缩。
放置算法:最佳适配、首次适配、下次适配
👇
伙伴系统。类似 2048 游戏。优点,分区数量不固定,灵活。分区释放后很容易合并,减少碎片。
利用了二叉树。
👇
非连续分配。允许一个进程使用非连续的物理地址空间,允许共享代码与数据,支持动态加载和动态链接。
如何实现虚拟地址和物理地址的转换。
- 软件实现(灵活,开销大):每一次内存的访问,还要额外地增加地址转换工作。
- 硬件实现(够用,开销小)
👇
分页。
目的:更好地利用内存,不考虑数据的实际意义,单纯一页一页划分。
👇
分段。代码段、堆、栈、静态数据区等。
目的:更细粒度和灵活的分离与共享。
段错误 (核心已转储)
👇
基于段寄存器的段式内存管理。
缺点:需要很多段寄存器
👇
基于段表的段式内存管理
段表和页表的区别:段比页大,段表里面的记录也就比页表少。
👇
交换分区。
目的:满足人们对内存无休止的增长。进程需要的内存比你物理内存还要大。
做法:覆盖(overlay)、交换(swapping)
覆盖是比较老的技术,只能发生在单个进程内部,程序员自己决定哪些部分覆盖。
交换的实现:
可将暂时不能运行的进程放到外存。
换入换出的基本单位:整个进程的地址空间。(PS :现在也允许将进程空间的一部分换出)
换出(swap out):把一个进程的整个地址空间保存到外存
换出(swap in):把外存中某个进程的地址空间读入到内存。
交换的时机:仅当内存空间不够或有不够的可能时换出。
交换分区的大小:存放所有用户进程的所有内存映像的拷贝。
程序换入时的重定位:换出后再换入时需要放在原处吗?采用动态地址映射的方法。
缺页异常、缺段异常:访问的地址没有映射到内存地址空间
付出的代价:缺页中断,操作系统将进程置于阻塞状态(需要去磁盘读数据到内存)。
当磁盘I/O发生时,另一个进程被分派去运行;
当磁盘I/O完成时,会发出一个中断,使操作系统将受影响的进程置于就绪状态。
使用交换技术,实现超过物理内存大小的进程运行;
使用非连续内存分配机制,实现只分配目前所使用到的地址空间,实现将一个程序的部分换出到磁盘。
进程空间(虚拟内存)被分成大小相等的块。页
物理内存被分成大小相等的块。帧(页框?)
不必要求连续的页必须放在连续的帧中。只要记录页和帧的对应关系就行。访问的时候去查映射关系就行了。
页和帧的大小相等,所以只要记录页和帧的对应关系就行了,内部偏移不用记录,两者是一致的。
页表:操作系统为每个进程,维护一个页和帧的对应关系。
a.0 -> 0
a.1->1
b.0->2
b.1->3
…
页表工作过程:
进程访问一个地址时,这个地址时虚拟地址,也就是页(虚拟地址的前半部分为页地址,后半部分为字节偏移量),
操作系统根据进程号和页地址,去页表查找,该进程的这个页对应的物理内存中的帧号。
在加上字节偏移,就得到实际的物理地址,
然后用这个物理地址去内存中拿数据,
然后返回给进程。
额外的开销:一次访问,需要访问两次内存。因为查页表也要访问内存。
连续分配的话,就没有查表这个开销,只要知道起始基地址就行了,后面都是连续的,直接基地址加偏移就行了。
对于页表,操作系统需要做什么?
至少要知道页表在哪里。