Linux 内核链表
链表
链表实际上是线性表的链式存储结构,与数组不同的是,它是用一组任意的存储单元来存储线性表中的数据,存储单元不一定是连续的,
且链表的长度不是固定的,链表数据的这一特点使其可以非常的方便地实现节点的插入和删除操作。
链表的每个元素称为一个节点,每个节点都可以存储在内存中的不同的位置,为了表示每个元素与后继元素的逻辑关系,以便构成“一个节点链着一个节点”的链式存储结构。
除了存储元素本身的信息外,还要存储其直接后继信息。因此,每个节点都包含两个部分,第一部分称为链表的数据域,用于存储元素本身的数据信息,这里用 data 表示,它不局限于一个成员数据,也可是多个成员数据。第二部分是一个结构体指针,称为链表的指针域,用于存储其直接后继的节点信息,这里用next表示,next的值实际上就是下一个节点的地址,当前节点为末节点时,next的值设为空指针。
普通链表
struct foo_s {
int data;
struct foo_s *next;
};
链表 = 节点1 –> 节点2 –>… (其中,前一个节点的指针域指向下一个节点的整个数据结构首地址)
节点 = data + next (其中,每个节点都是使用的相同的数据结构 struct foo_s)
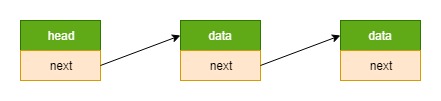
侵入式链表
struct list_s {
struct list_s *next;
} list_t;
struct foo_s {
int data;
struct list_s link;
};
链表 = 节点1 –> 节点2 –> … (其中,前一个节点的指针域指向下一个节点的指针域)
节点 = data + next (其中,节点可以使用不同的数据结构,如 struct foo_s、struct foo_s2,只要在它们内部都包含 struct list_s)
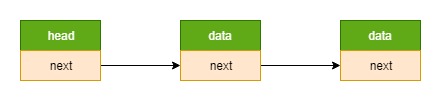
内核链表
内核中使用的链表大多数都是侵入式链表,不过要比上面的例子稍微复杂点,是侵入式双向循环链表,如下图
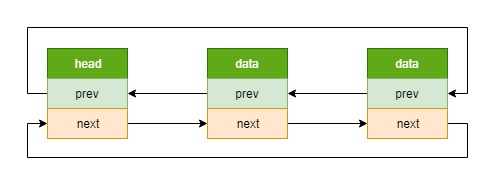
其数据结构如下,这里以 led_classdev 为例
struct list_head {
struct list_head *next, *prev;
};
struct led_classdev {
const char *name;
enum led_brightness brightness;
enum led_brightness max_brightness;
int flags;
...
struct list_head node; /* LED Device list */
...
}
这种链表是嵌(侵)入在其它数据结构中的,这些结构可能不相同。并且,这些数据结构中可以包含多个链表。
侵入式链表(内核链表)的好处
如果我们有一种数据结构 foo,并且需要维持一个这种数据结构的双链队列,最简单的、也是最常用的办法就是在这个数据结构的类型定义中加入两个指针,例如:
typedef struct foo {
struct foo *prev;
struct foo *next;
....
} foo;
然后为这种数据结构写一套用于各种队列操作的子程序。由于用来维持队列的这两个指针的类型是固定的(都指向 foo 数据结构),这些子程序不能用于其它数据结构的队列。换言之,需要维持多少种数据结构的队列,就得有多少套的队列操作子程序。对于使用队列较少的应用程序或许不是个大问题,但对于使用大量队列的内核就成问题了。所以,Linux 内核中采用了一套通用的、一般的、可以用到各种不同数据结构的队列操作。为此,代码的作者们把指针 prev 和 next 从具体的“宿主”数据结构中抽象出来成为一种数据结构 list_head,这种数据结构既可以“寄宿”在具体的宿主数据结构内部,成为该数据结构的一个“连接件”;也可以独立存在而成为一个队列的头。这个数据结构的定义在 include/linux/list.h 中
实例解析
我们以用于内存页面管理的 page 数据结构为例:
typedef struct page {
struct list_head list;
...
struct list_head lru;
...
} mem_map_t;
可见,在 page 数据结构中寄宿链两个 list_head 结构,或者说有两个队列操作的连接件,所以 page 结构可以同时存在于两个双链队列中。
一个疑问
有些小伙伴可能发问了:队列操作都是通过 list_head 进行的,但是那不过是个连接件,如果我们手上有宿主结构,那当然知道它的耨个 list_head 在哪里,从而以此为参数调用 list_add() 或 list_del();可是,反过来,当我们顺着一个队列取得其中一项的 list_head 结构时,又怎样找到其宿主结构呢?在 list_head 结构中并没有指向宿主结构的指针啊。毕竟,我们真正关心的是宿主结构,而不是连接件。
这就要提到内核中的两个神奇的宏了,这里我们不展开讲了,后面会详细介绍这两个宏的原理、用法。总之,通过这两个宏,在给定链表结构地址时,我们能够获取其宿主结构的地址。这样就能开心地操作宿主结构了。
2023-01-05 补充
示例代码位值:/home/liyongjun/project/c/C_study/linked-list/list2.h/
// main.c
...
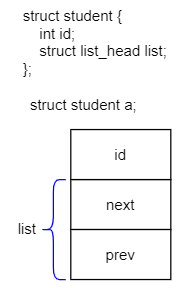
struct student {
int id;
struct list_head list;
};
int main(int argc, char *argv[])
{
struct student *new;
struct student *tmp;
struct student *tmp1;
int id_base = 2013313112;
LIST_HEAD(student_list);
for (int i = 0; i < 10; i++) {
new = malloc(sizeof(struct student));
new->id = id_base + i;
list_add_tail(&new->list, &student_list);
}
...
内核链表图示修正,之前画的有点问题。
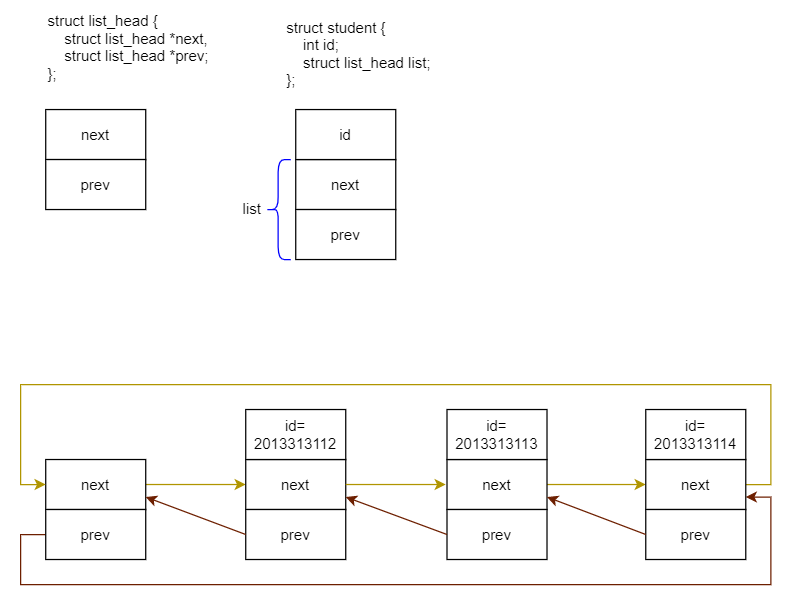
list_add_tail()
分析一下 list_add_tail(&new->list, &student_list);
功能:向链表尾部插入一个节点(entry,条目)
/**
* list_add_tail - add a new entry
* @new: new entry to be added
* @head: list head to add it before
*
* Insert a new entry before the specified head.
* This is useful for implementing queues.
*/
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
尾插就是将节点插入到链表最后,实际上就是 head 前面(因为是双向循环列表)。
/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
仔细看下 __list_add(),三个参数,new、prev、next,怎么理解这三个参数呢?
new 就是要插入的节点(新节点)
prev 就是新节点前面的节点
next 就是新节点后面的节点
所以这三个参数,都是站在 new 节点的角度来看的。想要把我 new 这个节点插入到链表中,那就告诉我,我的前驱节点 prev 以及我的后继节点 next。
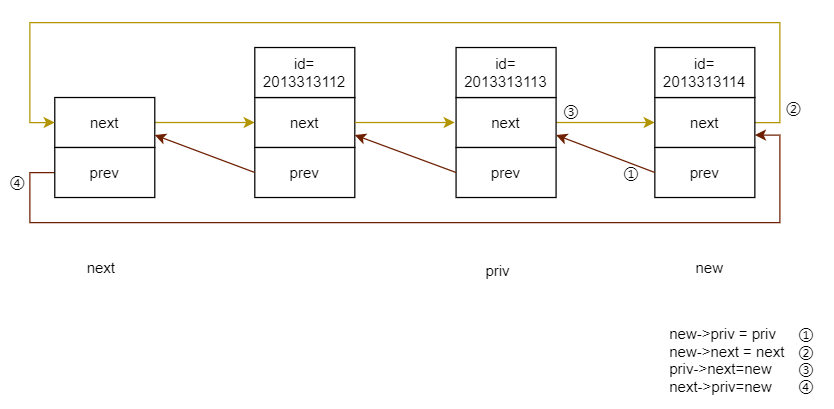
所以,__list_add() 很简单,只要传递给它三个参数 new、prev、next 就行了。
至于是 list_add_tail() 还是 list_add() ,全凭你传递给 __list_add() 的 prev、next 是谁来决定。
- prev 是最后一个节点(head 前面的那个节点)+ next 是头节点 = 尾插
- prev 是头节点 + next 是第一个节点(head 后面的那个节点)= 头插
list_for_each_entry()
/**
* list_for_each_entry - iterate over list of given type
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_head within the struct.
*/
#define list_for_each_entry(pos, head, member) \
for (pos = list_first_entry(head, typeof(*pos), member); \
&pos->member != (head); \
pos = list_next_entry(pos, member))
list_for_each_entry(),从 head 的下一个节点开始遍历,一直遍历到 head 为止。
list_first_entry()用来找出 head 的下一个节点。&pos->member != (head);判断是不是已经找一圈了list_next_entry() 当前节点的下一个节点
list_entry()
/**
* list_entry - get the struct for this entry
* @ptr: the &struct list_head pointer.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_head within the struct.
*/
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
list_entry() 就是 container_of()
功能:得到链表节点所在的结构的地址。
也就是下图中,由 a.list 得到 a 的地址。
list_del()
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
prev->next = next;
}
删除和插入是相反的操作,删除是建立四条连接(四个指针指向),删除则是断开这四条连接
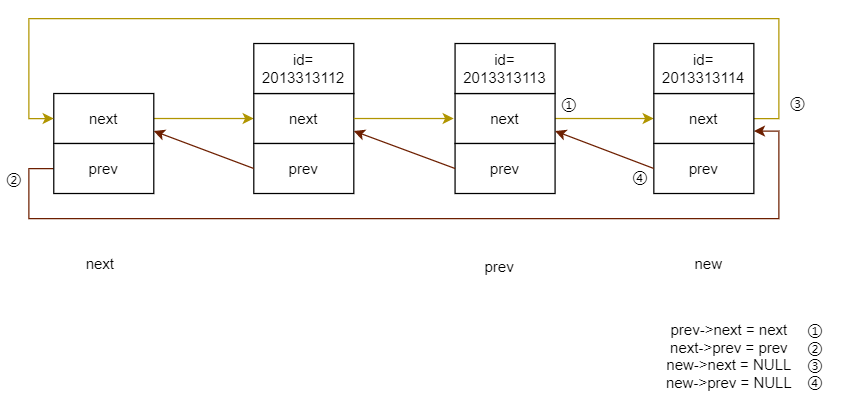
其中 ① ② 两步是在 __list_del() 中实现的。
list_for_each_entry_safe()
list_for_each_entry_safe(tmp, tmp1, &student_list, list) {
list_del(&tmp->list);
free(tmp);
}
注意,连续删除节点需要使用 list_for_each_entry_safe(),而不能使用 list_for_each_entry(),因为 list_for_each_entry_safe() 会多使用一个变量来记录被删除的那个节点的下一个节点,不然的话,当前节点被删除了,就不知道刚刚遍历到哪个节点了,就没法继续遍历了,会出现异常。
参考
Linux内核之数据双链表 | 《Linux就该这么学》
《linux 内核源代码情景分析》
((size_t) &((TYPE*)0)->MEMBER)